
Am 19. Januar zum Thema IT-Security & Datenschutz
Google Hacking, Datenpannen und Deep Web
Ich werde sehr oft gefragt, wie ich all die Sicherheitslücken und Datenpannen in all den Jahren aufgedeckt habe. Wie ich meine Suche nach Pannen und Lücken im Internet gestalte und wie es um sog. Securityscans bestimmt ist. In diesem etwas ausführlicheren Blogartikel von mir möchte ich den Lesern Einblick in die Welt des Google Hackings, sowie des Deep Webs geben…
Was genau ist Suchmaschinenhacking, bzw. Google Hacking?
Eine der Grundregeln für das Suchmaschinen-Hacking lautet: Mit minimalem Aufwand gewisse Möglichkeiten auffinden, nach frei öffentlichen Dateien und Informationen das Web zu durchsuchen. Gerade für das gezielte Aufspüren von sensiblen Informationen und Schwachstellen in Applikationen, Diensten- oder Konfigurationsschwachstellen hat sich sowohl in der Hacker-Szene als auch in der IT-Sicherheitsindustrie der Begriff “Google-Hacking” etabliert.

Ich will es mal so umschreiben: Mit der Suchmaschine Google lassen sich nicht nur alltägliche Dinge wie die Wettervorhersage, interessante Videos oder Nachrichten suchen. Viel interessanter ist das sog. “Deep Web” Searching.
Viele Administratoren in Unternehmen oder aber auch Privatanwender haben in ihrem internen Netzwerk diverse Dienste laufen. Das können u.A. FTP Dienste oder aber auch Fax, Mail oder Printdienste sein. In den meisten Fällen sind Unachtsamkeit sowie fehlendes KnowHow die Ursache, die dann das (Daten-) Fass zum Überlaufen bringen und den sog. Googlehackern Tür und Tor offen stehen lassen.
Stellen wir uns einen schlecht konfigurierten Webserver vor, oder eine NAS Festplatte oder einen FTP Dienst, der gleich von Haus aus mitliefert wird. Sollten hier die Berechtigungen auf der Ordnerebene falsch oder gar nicht gesetzt worden sein, so ist dieses schon eine sehr gelungene Einladung zum Herumstöbern des Robots von Google. Denn nicht nur herkömmliche Webseiten werden vom kleinen Google Robot im Netz erfasst, indexiert und später in der Suchmaschine gelistet. Ferner sind es auch die besagten Dienste und Applikationen, die normalerweise nicht für die Öffentlichkeit bestimmt sind und die internes aus dem Firmennetz preisgeben.
Bestes Beispiel hierfür.
Als ich mich vor gut 4-5 Jahren mit dem Google Hacking begonnen habe, da gab es zahlreiche Sicherheitslücken in Videoüberwachungskameras. Sog. IP-Kameras, sowie in PHP Anwendungen und insbesondere in offene Druckern, bzw. in Printservern, die vom Netz (Gogglesuche) aus angesprochen werden konnten. Natürlich nicht einfach so. Es befarf schon einer gewissen Suchtechnik.
So bin ich auf unzählige Überwachungskameras in Unternehmen gestoßen, an Überwachungskameras in der Industrie, in der Forschung, an Universitäten und sogar Fußballstadien und auf der „Intensivstation“ gab es auch noch Kamerasysteme zu bestaunen. Das waren mitunter schon ziemlich schwerwiegende und unverantwortliche Sicherheitslücken, bzw. Konfigurationsfehler, die sich da im Netz reihenweise breit gemacht hatten.
Skurille Datenpannen in Videoüberwachungssystemen (gefunden via Googlehacking)






Interessant waren auch die Drucker, die in der ganzen Welt verteilt (offen) herumstanden und mittels simplen Googlesuchbegriffen aufgefunden und geöffnet werden konnten. Auch ein großer Teil der Drucker hatte Fax und Scan-Einheiten, so dass man sich auch die letzten 100 gesendeten Faxe im .pdf Format samt den dazugehörigen Faxnummern anschauen konnte. Schön waren auch die Scan, die meist eine Ordnerebene höher abgelegt waren. Nicht selten waren in diesen Dokumenten auch Schriftwechsel, bzw. Verträge zu besichtigen.
Der untere Teil des Interneteisbergs – Das Deep Web
Mit dem Begriff „Deep-Web“ versteht man die Tiefen des Internets, in diese man als „Standard Internetnutzer“ a) nur durch Zufall gelang und b) nur durch bestimmte Suche oder einschlägige Websites, die einem die Tür dorthin öffnen. Man kann diese Form des Internets auch als das versteckte Web bezeichnen (Hidden Web oder Invisible Web).

Im Deep Web werden die über Suchmaschinen zugänglichen Webseiten Visible Web (Sichtbares Web) oder Surface Web (Oberflächenweb) genannt. Das Deep Web besteht zu großen Teilen aus themenspezifischen Datenbanken (Fachdatenbanken) und Webseiten, die erst durch Anfragen dynamisch aus Datenbanken generiert werden. Grob kann das Deep Web unterschieden werden in „Inhalte, die nicht frei zugänglich sind“ und „Inhalte, die nicht von Suchmaschinen indiziert werden“. Die Größe des Deep Web kann nur geschätzt werden – es wird davon ausgegangen, dass es ein Vielfaches des direkt zugänglichen Webs umfasst. Suchmaschinen und ihre Webcrawler werden jedoch ständig weiterentwickelt, daher können Webseiten, die gestern noch zum Deep Web gehörten, heute schon Teil des Oberflächenwebs sein.
Die Entwicklung des Suchmaschinen-Hackings
Suchmaschinen Hacking ist nichts anders, als das gezielte Suchen nach genau solchen Datenbeständen des Deep Webs. Bekannt geworden ist diese indirekte Methode an relevante Daten zu gelangen, ohne direkt auf die IT-Systeme zuzugreifen, durch den amerikanischen Hacker und Sicherheitsspezialisten Johnny Long, der dafür den Begriff “Google Hacking” geprägt, bzw. eine Google Hacking Database entwickelt hat. Reichlich Angriffsmaterial liefert vor allem die unübersichtliche Zahl der in den Unternehmen vorhandenen Webserver. Die einzige Kunst des neugierigen Rechercheurs besteht darin, mit entsprechender Geduld passende Suchanfragen zu produzieren, um die genannten Seiten aufzuspüren.
Ein sehr gutes Werk das ich wärmstens empfehlen kann ist das Buch von Johnny Long (Google Hacking)

Das Buch - Google Hacking
Dieses ist schon in der 2. Auflage erschienen und komplett in Deutsch gehalten und kann z.B. hier bezogen werden.
Was sind die goldenen Regeln beim Google Hacking?
Wichtig ist zu wissen, wie eine Suchmaschine aufgebaut ist, bzw. wie sie auf gewisse Eingaben im Suchfeld reagiert. Eine Google Hacking Suche kann nur so effizient sein, wie meine Eingabe in die Suchmaske, bzw. meine Suchoperatoren (ich nenne diese übrigens Suchcombos). Man muss zum einen wissen was man genau suchen möchte, parallel muss man hierzu das zu suchende System kennen. Also Dinge wie „Was macht das zu suchende System aus, was ist die Besonderheit an diesen Systemen, wo stecken die Schwachstellen oder die Einzigartigkeiten? Also, erst wenn man das System kennt kann man gezielt auf die Suche gehen. Wenn man das System kennt, dann muss man zusätzlich auch die Google Combos beherrschen. Also genau wissen, wie und wann diese in der Praxis einzusetzen sind.
Ich habe mich auch lange Zeit mit den diversen Suchelementen herumgeschlagen, herumprobiert und vieles gelernt. Erst später, wenn man sich sicher ist zu wissen was man genau tut, fängt es an Spaß zu machen und die ersten großen Erfolge lassen sich verzeichnen. Interessant wird es auch dann, wenn man mehrere Suchparameter zusammenstellt, bzw. koppelt und in diese sog. „Combos“ verwandelt. Das ist wie im Computerspiel „Streetfighter“ von Nintendo … man muss erst mal einen Move lernen und perfekt ausführen können bis man sich dem zweiten Move widmet. Erst wenn man den 2. und 3. Move erlernt hat, entsteht eine einzigartige Combo, die dem System die Goldnuggets entlockt und den Gegner in die Knie zwingt.

Also hier zunächst die Grund-Moves liebe Samurais:
- filetype:
Mit filetype lassen sich bestimmte Dateitypen finden, wie z.B. Textdateien
Beispiel: filetype:txt - Das Plus: Mit + lassen sich alle Webseiten finden, die ein bestimmtes Wort enthalten.
Beispiel: +FBI +Agent - Das Minus: Mit – werden nur Seiten gefunden, die ein bestimmtes Wort nicht enthalten.
Beispiel: -public –user - intitle:
Per Intitle: lässt sich das <title> tag im Quelltext der Webseite durchsuchen. z.B. die index.htm
Beispiel: intitle:index - intext:
Mit intext: findet man bestimmte Wörter auf einer Webseite.
Beispiel: intext:Hacker - inurl:
Über inurl: lassen sich Wörter in einer URL festlegen. (z.B. Ordner bin und etc)
Beispiel: inurl:etc inurl:bin - site:
Mit site: kann man auf bestimmten Domains suchen oder Länder ausschließen.
Beipsiel: site:com site:de - Anführungszeichen “”
Mit “” lassen sich aufeinander folgende Wörter suchen.
Beispiel: “index of”
Kommen wir nun zur Trainingseinheit II, den Combos
Das die oben genannten Befehle (Moves) alleine nicht viel bringen, das dürfte wohl nun jedem von Euch klar sein, also müssen wir kombinieren und uns fleissig die Combos bauen.
Beispiel 1:
intitle:”index of” +etc
Über solche Ergebnisse kann man sich nur wundern! Warum gibt es immer noch Systeme auf denen man ohne Probleme sich über Google, die passwd anschauen kann? Für potenzielle Cracker sind solche Umstände ein El Dorado.
Beispiel 2:
inurl:/control/userimage
Hier gelangen wir direkt in das Kontrollcenter diverser Videoüberwachungskameras, in dem wir einen gewissen Begriff in der URL Zeile suchen.
Beliebt ist die Variante, ganze Passwortlisten über Suchmaschinen auszulesen. Beispielsweise bringen folgende Suchanfragen Passwortlisten zutage:
inurl:/_vti_pvt/user.pwd
inurl:/_vti_pvt/administrators.pwd
inurl:/_vti_pvt/service.pwd
Suchparameter wie “inurl:”, die für das Hacking benötigt werden, werden nicht nur von Google, sondern auch von nahezu allen anderen Suchmaschinen unterstützt. Also auch diese Dinge einfach in anderen Suchmaschinen mal testen.
Kurze Beispiele: Interessante Suchbegriffe könnten z.B. auch diese nachfolgenden Google-Kombinationen sein:
“not for distribution” confidential filetype:pdf
directory filetype:xls inurl:SEO
Per Hand suchen oder einen Crawler die Arbeit übernehmen lassen?
Sicherlich kann man sich die Frage stellen, ob man das alles nicht automatisiert, bzw. mittels einer Software betreiben möchte, bzw. man eine automatische Suche favorisiert. Das funktioniert in der Regel auch und gibt es schon seit ein paar Jahren. Das Zauberwort nennt sich Goolag Scanner. Aber Vorsicht vor dem Budenzauber. Handmade Searching ist weitaus spannender und effektiver.

Goolag Scanner Start
Dieser besagte Goolag Scanner (Google Hacking Tool) wurde vor einigen Jahren von der berühmt berüchtigten US Hackergruppe mit dem Namen “Cult of the Dead Cow (cDc)” vorgestellt und zum Download im Internet angeboten.
Cult of the Dead Cow Logo
Das Tool scannt gewünschte Internetdomains nach offenen Türchen und Verwundbarkeiten ab. Man kann also sagen, dass es sich hierbei um ein Penetration-Testing Tool handelt. Kennwörter werden nicht geknackt, bzw. das besagte Tool klopft lediglich gewisse “offene” Dienste und Applikationen ab.

Goolag Scanner in Aktion
Ein richtiger Hack oder ein Crack stellt der Dienst des Tools (nach meiner Meinung) nicht dar. Es ist mehr ein Crawler und ein technisches Tool zur Fehleranalyse im Bereich Webserver und Dienste.
Ganz aktuell – Das Problem mit den NAS Systemen
Zum Schluss möchte ich noch auf eine ganz aktuelle Sicherheitslage aufmerksam machen. Wenn man rund 4-5 Jahre das Google Hacking betreibt und immer weitere und kompliziertere, in sich verschachtelte, Combos für die Suche entwickelt, so lernt man auch vieles über die Systeme dort draußen im Web kennen. Umso mehr machen mir ganz aktuell sog. NAS Systeme Kopfzerbrechen, bzw. Magenschmerzen in Bezug auf IT-Security.
Kurz angerissen: Was sind NAS Systeme?
Network Attached Storage (NAS) bezeichnet einfach zu verwaltende Dateiserver. Allgemein wird NAS eingesetzt, um ohne hohen Aufwand unabhängige Speicherkapazität in einem Rechnernetz bereitzustellen. Im privaten Bereich finden sich ebenfalls sehr oft NAS Systeme wieder. Wer einmal durch die großen Elektronikmärkte wandert und in der Computerabteilung halt macht (in Höhe der Regale mit den verschiedenen Festplatten) wird auch dort auf diese besagten NAS Festplatten stoßen. Meist schwarze oder graue Gehäuse, in denen eine oder mehrere Festplatten verbaut sind. Zuhause oder in der Firma kann man diesen „Festplattenwürfel“ dann an einen Switch oder Router etc. anschließen via Netzwerkkabel. Somit taucht diese Festplatte (NAS) im Netzwerk auf und die Computer im lokalen Netzwerk können dann diesen Netzwerkspeicherplatz für Sicherheitskopien oder zur Datenablage benutzen etc.
Wo liegt das Problem bei den NAS Systemen genau?
Meine persönlichen Erfahrungen haben gezeigt, dass immer mehr NAS Systeme mit speziell hierfür geschriebener Software auf den Markt kommen. Also einer Weboberfläche, wie wir diese von z.B. Routern her kennen. Über den Webbrowser lässt sich dann meistens mittels der IP das Frontend der NAS Festplatte aufrufen. Das ist aus der Sicht des Nutzers (Admins) eine ganz tolle Sache, denn auf der Konfigurationsoberfläche lassen sich viele spannende Sachen einstellen (leider aber auch verstellen!).
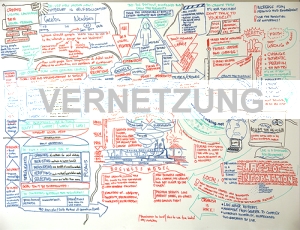
Nachfolgend eine Skizze von mir, wie ich NAS Festplatten im Web ausfindig mache

Erinnert Ihr Euch noch an die damalige Zeit, als die WLAN Netze wie Pilze aus der Erde schossen, also als es überall freie und ungesicherte Funknetze gab?!
Wieso gab es diese? a) neue Technik b) mangelndes Sicherheitsbewusstsein c) Unwissenheit bzgl. der Absicherung. d) Plug & Play und es lief, Niemand machte sich über das Thema Verschlüsselung Gedanken. Erst mit steigenden Medienberichten und Blogartikeln handelten auch die Hersteller und liefern nun meistens die Geräte mittels Kennwort aus. Hier ist es aber auch wichtig, nicht das Default Kennwort (also das ab Werk) später so unverändert stehen zu lassen. Es gibt genügend Default Password Databases im Netz die eine megamäßige Sammlung an Herstellerkennwörtern liefert.

Online Default Password List
Ich schweife ab. Also um auf den Punkt zu kommen. Ich vergleiche das derzeitige Problem mit den offenen FTP Servern, bzw. den offenen NAS Systemen, mit den offenen WLAN Netzwerken von Damals. Die NAS Festplatten werden (je nach Preis und Ausstattung) mit einem FTP Dienst ausgeliefert. So dass der Kunde auch aus der Ferne (mit fester IP oder DynDNS) auf die heimische Festplatte zugreifen kann. Leider sind die FTP Dienste der NAS schlecht programmiert oder schlecht für den Laien zu konfigurieren. Schnell ist mal das Häkchen FTP gesetzt, ohne sich den Folgen bewusst zu sein, dass nun das gesamte Internet auf die Daten zugreifen kann. Denn standartmäßig lautet der User: Anonymous und das dazugehörige Kennwort: password
Wann passiert der Daten-GAU?
Die Frage ist nicht wann der Datengau passiert, sondern wie oft und in welchem Zeitraum eine Lücke geschlossen wird. Leider sind schon viel zu oft Daten abhandengekommen in solch einer Form, wie soeben von mir beschrieben.
Man muss sich das in der Praxis wie folgt vorstellen:
Mitarbeiter Peter Mustermann arbeitet in einer Firma an einem Projekt, bzw. an einer neuen Spielekonsole. Peter Mustermann ist für die Programmierung, bzw. für die Webschnittstelle zuständig und kümmert sich somit auch um das Thema Virenschutz, Ports und Firewalls. Herr Mustermann fertigt im Laufe seiner Projekte unzählige Daten und Dokumente an. Angefangen von Word, Excel, Powerpoint Dokumenten, bis hin zu MS VISO Zeichnungen und MS Project Daten. Aufzeichnungen von Meetings, Designstudien, Programmcode etc. Alles schön sortiert in unzähligen von Ordnern. Das alles liegt auf dem Laufwerk des Mitarbeiters Mustermann, bzw. auf dem gut gesicherten Firmenserver. Eines Tages kommt Stress auf, das Projekt muss fertiggestellt werden, die Daten müssen also mit nach Hause, bzw. es muss im (inoffiziellen Homeoffice) weitergearbeitet werden. Aber vielleicht gab es auch garkein Stress, sondern Herr Mustermann war so stolz auf seine Arbeiten, dass er sie einfach als sein Eigen ansah und mit nach Hause nehmen wollte. Zuhause legt Herr Mustermann dann alle seine Daten (die er zuvor mit dem USB Stick kopiert hatte) auf seiner NAS Festplatte ab. Hierzu bieten die meisten NAS Festplatten die Funktion (Copy from USB). Also mach mir eine schöne 1:1 Kopie (Backup) meines USB Sticks auf die NAS Festplatte.
Ich möchte Euch noch etwas mit auf den Weg geben …
Hier findet Ihr ein .pdf Dokument, das zahlreiche (schon fertige) Suchkombinationen enthält. Das solle Anreiz genug sein, sich mit dem Thema Google Hacking einmal selbst auseinander zu setzen, bzw. vorab kleinere Erfolge in diesem Bereich zu erlangen.
So nun aber viel Erfolg bei der Googlesuche …
Das Kommentarformular ist somit freigeschaltet und ich bin auf Euer Feedback gespannt.
Über den Author
Mein Name ist Boris Koch und ich lebe Social Media. Themen wie Datenschutz im Internet und IT-Security sind aber auch gleichermaßen mein Steckenpferd. Mein Leben ist eine Mischung aus Technikliebe und das Leben im modernen Lifestream des Web 2.0
- Mehr bei






Facebook Kommentare:

Sehr schöne Zusammenfassung Boris. Habe selbst einiges davon bei mir in Vorträgen immer wieder eingearbeitet. Weiter so
Marko
Vielen Dank, interessanter Artikel!
Habe mich selbst immer mal ein wenig mit Google Hacking beschäftigt, aber nie intensiv – dazu fehlte mir die Zeit oder die Lust.
Grüße Nico
Danke für den schönen Artikel … habe in einem Blog-Post auch einige Tipps zu Google veröffentlicht, habe mich jedoch nicht so sehr mit dem Thema “Hacking per Google”, daher hab ich diesen Blog-Post verlinkt …
-> http://suckup.de/blog/2010/02/14/google-hacks-und-tricks/
[...] Werten sprechen kann. Interessant könnte auch der Artikel von Boris über das Deep Web und Google Hacking sein…Ich melde mich zurück wenn es mir besser geht da ich euch Leser nicht langweilen [...]
Hier ne kleine Seite bzgl. Google hacks…
http://0xdeadheap.net/ghack.php
Viel Spaß damit
Hallo Herr Koch,
Ihr Artikel ist absolute Klasse. Insbesondere Ihr PDF Dokument hat’s in sich. Sehr umfangreich. Ich werde die von Ihnen beschriebene Problematik in meinen Security Seminaren aufgreifen und auf Sie verweisen.
Machen Sie weiter so!
Viele Grüße aus dem Harz
Philipp Dresner
[...] Boris Koch [...]
I like the forum and it helps
But what if you are trying to get a
programs or files from a specific
website for free without using torrents
We have a public CGI:IRC client for anyone to use. You can connect to any IRC server!
http://webirc.shellcode.eu/cgi-bin/irc.cgi
[...] Weitere Infos zum Thema Google Hacking (Ein älterer Blogbeitrag von mir) [...]
Wirklich interessant! Das Thema Hacking interesiert mich ja schon länger, also nicht nur Google Hacking. Und ich würde gerne lernen, ich brauche input, input, input! Alles was sich mit dem Thema hacken (für Anfänger) beschäftigt, vielleicht könnte mir jemand diesbezüglich weiterhelfen.
Für Links zu bestimmten Anfänger-Guides oder ähnliches würde ich mich sehr freuen.
[...] Grund der E-Mails? gulli:board-User Boris Koch hatte uns mitgeteilt, dass er beim Google-Hacking über einen öffentlich zugänglichen FTP-Server der ESA stolperte. Mit Hilfe von modifizierten [...]
[...] Boris Koch [...]